AI and Med Pods
Elysium and Prometheus were two movies that showed marvelous things. One of the most fascinating thing in those two movies were Med Pods. This is where the subject can lie down on the Med Pod and without human intervention it diagnoses the illness or situation and work on steps to address the situation and finally action on it. Imagine a world where we see this is available to the most remotest place in the planet(or solar system or even in an airplane or cruise) where people can have access to better health anytime. The bad news is that there are no Med Pods as we imagine it to look like but the good news is that there are technologies today that can help in identifying issues in software systems.

Diagnosis
The first step to do any troubleshooting is diagnosis. To perform diagnosis, you review series of data from various sources. In the medical world, you would get your blood or nasal swap tested for variety of parameters, run a CT scan, X-ray, endoscopy and more and finally identify the illness, rule out other issues that may impact and then find and execute the cure. The same would apply when something is broken anywhere in your surrounding world, you gather data from variety of sources, observe and analyse them and finally fix it(think about the electric safety switch tripping).

Diagnosis is no different in the world of software systems. You would start by collecting useful data from key sources, observe and analyse them and finally identify the issue. The fundamentals are very simple, the problem lies in the complexity of the system.
Complexity

Think of a simple website where you sign up and see stories that only you subscribed to. It would typically involve a frontend web framework, talking to an API endpoint which would then forward the request to a function, container, server or a managed platform through a load balancer and/or a CDN. We don’t want to forget the infamous DNS either. You will also involve a database, authentication and other third party services like adverts, payment, code integration and deployment systems.
Now, think about what all could possibly go wrong in this simple setup. The answer is - anything. Anything could potentially go wrong depending on the situation. The server where this is hosted may have issues. Within the server, the issue may be caused by CPU or memory saturation, network limits or errors, disk space or latencies, OS or a bug in the App itself. I just gave an example of a server, now try collecting key metrics from other components like Load balancer, CDN, User performance, application, database, DNS, third party services etc.
If a simple application may involves all these, think about the large applications that you have seen which includes many different services and dependencies on many different platforms and architectures. The number of services, microservices and processes of these would be in hundreds and thousands and it would get harder and harder to collect and report key data(logs, metrics and traces).
Non AIOps
There are many terminology in IT Operations that would already make your head spin(BizDevSecOps, CloudOps, DevOps, ITOps, NoOps) and thus it is better to categories one that has AI and one that hasn’t. In fact, AIOps is more of a foundational component to the *Ops processes as it focuses on automation and intelligence across the platform and not necessarily on a specific methodology.
In a diagnostic platform (think observability or monitoring platform) that does not have AI, collecting key data is just one piece of the puzzle, there is no point in collecting all these data without visualising and being notified when an anomaly is occurring. The platform needs to be told on what to monitor, how frequently to sample the data and when you want to be notified on what anomaly.
Is it simple to define and configure these?
A Non-AIOps system would require you to update the configuration based on what you want to monitor, how frequently you want the data, tell what you want to be defined and called as an anomaly.
Everything is a file.

There is always fun, excitement and gratification in modifying config files initially but after a certain point and given the scale of the systems we have seen, it becomes painful, error prone and introduces blind spots and all that we would like to do is exit from the file without making changes as we get intimidated by the countless options we see on the file.
Secondly, it wouldn’t automatically know the dependency, topology and relationship. One would have to define the thresholds, benchmarks, anomalies and alert rules. When there is a system degradation, one would have to swim through the alert channels, correlate the data, create a hypothesis of the potential cause, draw a conclusion and finally remediate it to bring the system back to normalcy.
AIOps
Why do we even need AIOps?
As you have seen, diagnosing a problem in software systems require lot of parameters to be configured and defined. Only in the next stage can we actually find the root cause of the problem. This is difficult to scale as new products, solutions are released and made available which introduces further complexity in the system. Think about a new product that your Cloud provider launched that you want to make it part of your solution. This is the reason why AIOps is very essential today.
What kind of intelligence are we expecting here?
An AIOps enabled platform would automatically collect data from all the various sources which it deems to be relevant. It would then introduce automation by detecting all the different services, processes, topologies, technologies and dependencies without any human intervention.
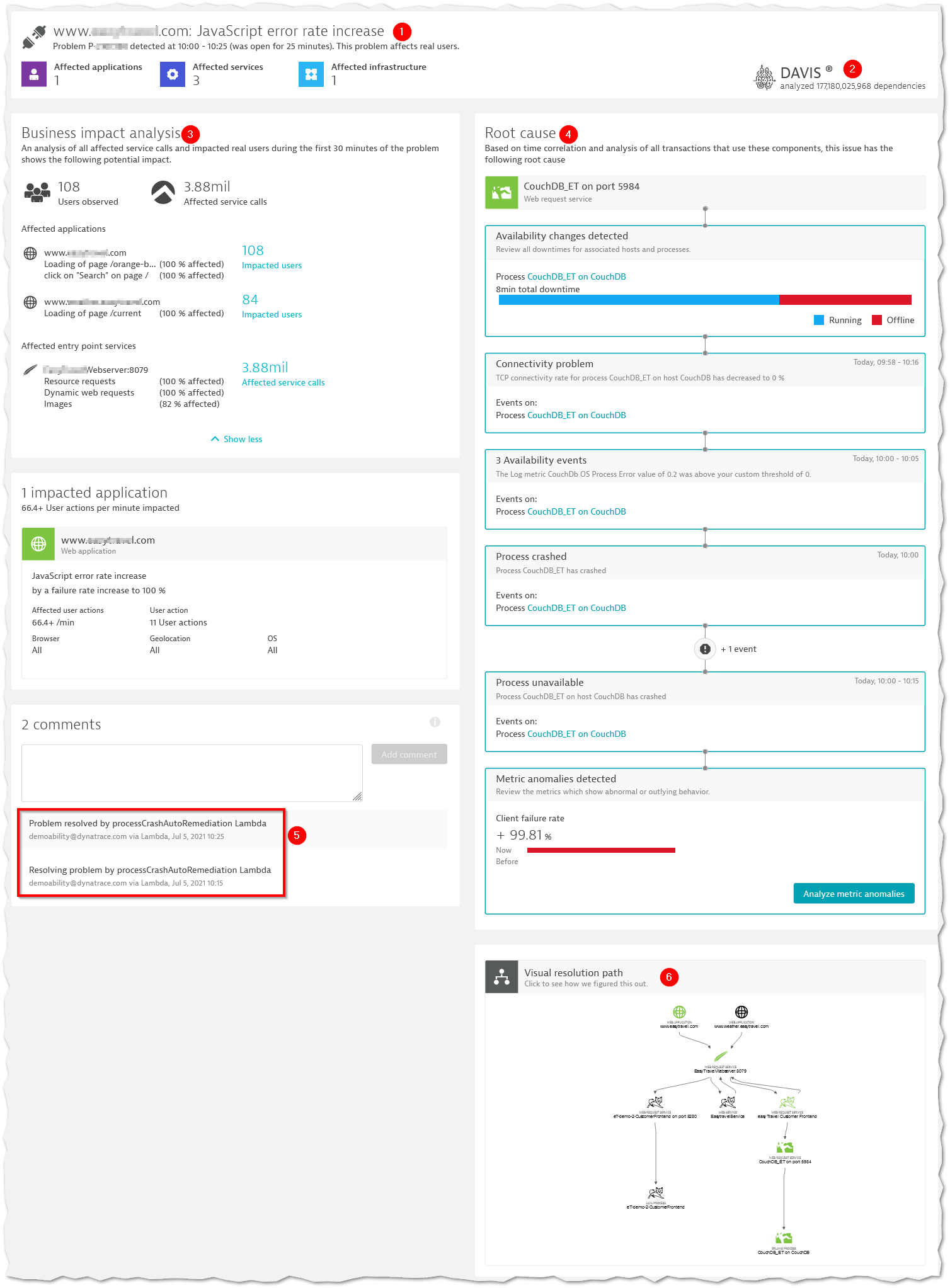
Because it knows the system, services and dependencies really well, it will have the maturity to define the thresholds by using the inbuilt AI engine. The real potential is revealed when things actually go wrong. This is where the AI would find out and conclude the root cause of the underlying problem so you can focus on addressing that issue instead of sending alerts from various sources and you figuring out what could be wrong. Technologies on software systems have improved so much today that it can even be configured to remediate the issue with no manual intervention (think NoOps). The screenshot above shows a problem card in Dynatrace that analyses 177 billion dependencies through AI to determine the root cause. The left bottom section shows the remediation that it took to resolve the problem automatically.
Are we going to lose Ops jobs to machines?
The complexity of systems since the information age has always been is increasing which means that we need more developers and operators to build and manage them at greater scale. We still need more operators to manage the systems as they focus on maintaining their service level objectives and finally improve resiliency.
AIOps is the next logical step because finding issues today in systems which have variety of dependencies, complex topologies and hundreds of microservices is not scalable with traditional file configuration and creating manual alerts. AIOps is an enabler which helps us find and remediate issues faster and reduce the downtime.
Do we have a Med Pod for Systems today?
The scope of robots in the medical world has increased a lot in the past few years but an actual Med Pod that completely diagnoses and remediate ailments is still a work in progress. However, with technologies like Dynatrace which has AI at the core, developers and operators today can do more than just looking at dashboards, traces and alerts. They could spend least amount of time on configuring and finding anomalies in dashboards but rather get answers and root causes right out of the box and focus on building better resilient systems.